
Why PostgreSQL Search Isn’t Enough - A Case for Purpose-Built Retrieval Systems
Instacart’s recent blog posts and InfoQ coverage paint a picture of a simplified, cost-effective search architecture built entirely on PostgreSQL. It’s a clever consolidation — but also a cautionary tale. For most organizations, especially those with complex catalogs, high query diversity, or real-time ranking needs, this approach is not just suboptimal — it’s misleading.
Postgres is a relational database, not a retrieval engine. Treating it like one introduces architectural debt that will eventually come due.
While the engineering effort is commendable, the approach is dated and fundamentally flawed for organizations aiming to deliver scalable, relevance-driven search experiences. If anything, it underscores why retrieval and ranking are essential — not only for ecommerce, but also for emerging applications like Retrieval Augmented Generation (RAG).
Too often, companies invest in “the new shiny” while ignoring opportunities to refactor and upgrade their existing technology investments. They’ll pour money into agentic AI while underfunding enterprise search for their employees. Instacart’s architecture may reduce infrastructure overhead, but by sidestepping purpose-built retrieval systems, it exposes the flaws that inevitably come with using Postgres for search.
The Temptation of Simplicity
PostgreSQL’s built-in full-text search features (tsvector, tsquery, GIN indexes) make it easy to add basic search capabilities without introducing new infrastructure. For simple use cases or internal tools, that might be enough.
Instacart outlined how they used Postgres to handle tokenization, ranking, and filtering all within the database. The convenience is real — but so are the tradeoffs.
Where PostgreSQL Falls Short
1. Relevance Ranking
Postgres includes basic ranking functions (ts_rank, ts_rank_cd) that can score documents, but these are limited compared to the industry standard. Its ranking is simplistic and lacks support for decay functions, learn-to-rank pipelines, and cross-index scoring. In this regard, Postgres does not provide sophisticated relevance scoring.
Modern retrieval systems like Elasticsearch, OpenSearch, Qdrant, and Vespa natively support BM25 for lexical relevance. Beyond BM25, they offer decay functions, learning-to-rank models, pre-filtering of results, and cross-index search — all critical for delivering high-quality, scalable, consumer-facing search.
Instacart’s own experience illustrates the problem. Their autocomplete produces irrelevant suggestions (searching for “kolache” yields “Brazil cheese bread” and “Texas toast”), and their ranking frequently surfaces off-target results. These flaws aren’t unique to Instacart — they’re the natural outcome of relying on Postgres as a search engine. Without a retrieval layer designed for relevance, customers inevitably encounter friction.
Hybrid search with pgvector can help, but it requires hand-rolled orchestration. Modern systems integrate lexical + vector scoring natively, balancing recall and precision. Without that balance, hybrid search produces noise (a ketchup hotdog is not the same as a mustard hotdog). Retrieval engines solve this problem directly.
2. Advanced Features
Postgres has extensions for trigram-based fuzzy matching, but it falls short on the advanced features that modern search requires. It lacks first-class synonym filters, multi-lingual stemming, typo tolerance, and personalization — all of which are available out of the box in purpose-built engines.
The difference is clear: similarity is not the same as synonymy. King is similar to Queen, but they are not synonyms. Ketchup and Catsup are synonyms, while Mustard is similar to Ketchup but irrelevant in context. Systems that can’t make these distinctions confuse customers and mis-rank results.
And in ecommerce, relevancy isn’t just about matching terms — it needs to be personal. Every query, for every user, should be ranked differently. Retrieval systems provide the tools to make that possible.
3. Observability and Tuning
Postgres offers query introspection through EXPLAIN/ANALYZE, but it lacks the rich observability, monitoring, and tuning frameworks that retrieval systems provide. Elasticsearch, OpenSearch, and Vespa expose detailed insights into query performance, index health, scoring distribution, and user behavior.
This isn’t a nice-to-have — it’s the backbone of modern search. Observability makes it possible to measure whether changes are “moving the needle.” It’s also the foundation for training learn-to-rank models that adapt relevance over time. Without this visibility, search becomes a black box.
Instacart’s relevance flaws are the direct result: without proper observability, teams can’t iterate quickly, can’t validate improvements, and can’t systematically tune for better results.
The Retrieval System Advantage
Retrieval systems like Elasticsearch, Vespa, OpenSearch, and Qdrant are built for this. They separate indexing from storage, support distributed architectures, and offer rich APIs for querying and ranking.
There’s an inherent tradeoff — the data needs to be shipped to a dedicated system — but the payoff is clear. Purpose-built retrieval engines outclass and outperform databases (or the marketing term “vector databases”) because they offer the capabilities required for real-world search.
Why This Matters
Friends Don’t Let Friends Use a DB for Search
Poor relevancy directly impacts business outcomes. When users can’t find what they want, they churn to competitors. For brands, that means higher transaction costs at best — and lost sales at worst. Relevance is not just a technical feature. It’s a revenue engine.
Here are a few examples of failed relevancy:
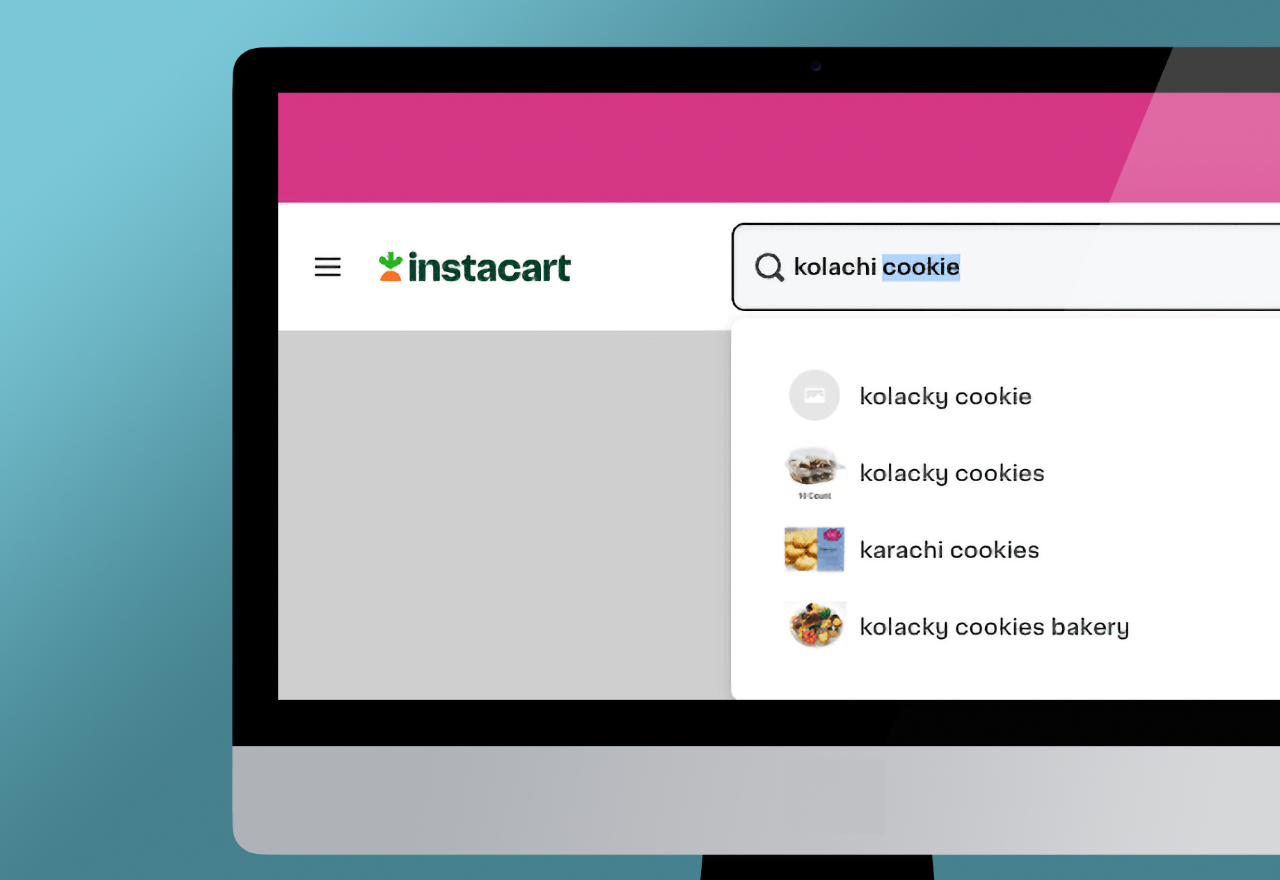
So while Instacart’s article is a great example of engineering ingenuity, it’s not a blueprint for scalable search. PostgreSQL is a relational database — not a retrieval system. This is another example of wheel reinventing. If search is central to your product or platform, invest in tools that are purpose-built for it.
If you’d like a second opinion before heading down the wrong path, contact us. MC+A is agnostic toward implementation — maybe PostgreSQL is enough for your use case, maybe Elasticsearch is the right fit, or maybe you just need to optimize what you already have. With the right adjustments, you can unlock significant gains in both performance and relevancy.