
The Future of Search: Vision Models and the Rise of Multi-Model Retrieval
Summary
Vector search technology is evolving with the emergence of ColBERT and ColPali, two systems that are revolutionizing how we process and retrieve information. ColBERT introduces a "late interaction" approach that breaks down both queries and documents into token-level representations, enabling more efficient processing of large documents while maintaining accuracy. ColPali builds on this by incorporating vision model capabilities, processing documents as screenshots allowing a better understanding of visual elements like tables and graphs.
These systems offer significant improvements in search relevance and the ability to handle both text and visual content and are particularly valuable for use cases involving legal documents, regulations, and financial data.
How ColBERT and ColPali are Redefining Retrieval Systems
TechnologySearch technology powered by vector search has become an essential component of how we access and understand information. Vector embeddings and the models that create them have gone through an unprecedented pace of innovation. Lucene and other vector storage systems have sprung out with smaller representations of the vectors with byte and bit vectors, but a more significant shift has begun combining Vision Model outputs with multi-model retrieval systems. These systems can handle a large document more natively, with semantic understanding that was only a dream just a few years ago.
This innovation causes you to read something mentioning “State of the Art” (SOTA) and “Novel approach” daily. While SOTA is now overused, fundamentally there are these three points to consider with anything new, which are:
- What is the practical application of the innovation
- What is the cost of operating this innovation
- What is the benefit to this innovation
We hope to address these points while sharing something we are excited about, which is combining multi-model retrieval and Vision Models.
Why is multi-model better than single model?
This is an excellent question, or even “why should I care?”. Any model trained to specific tasks with specific training data. Hugging Face has no shortage of models for this reason. If you are building a retrieval system, choosing the model that creates your embeddings that are store in your vector database is an important choice. This traditionally must take at its input some form of a string of text.
So, image retrieval systems (like when you search for stock art) have traditionally used features/metadata extracted from the images, such as content labels, tags, and image descriptors, to compare images and rank them by similarity. Multimodal embedding differs in that the vector representation can be generated from both images (or video) and text. This makes them compatible with text-based searches. So now you can search for an image with text or an image to find text. Therefore, if you use a multi-model approach allows the benefits of vector similarity search on the image.

This specialization leads to higher precision for finding what you are searching for, which is difficult to achieve using just one generalized model. Leading the way in this approach are models like Colbert and Colpali and with them a shift to the systems that can support them as they contradict what other vector systems can support.
Truly State of the Art (SOTA) Ranking as of a few weeks ago
These models create a new method of ranking which differs and as we just mentioned, saying something is SOTA is generally meaningless given the speed of the industry and the ability of any one idea to gain significant traction. That said, the general SOTA approach to ranking involves something similar to:
- Executing a BM25 keyword search as a result set
- Executing a KNN search against a vector field as a result set
- Picking the top results of those two and merging them
- Reranking the ranking order through a ranking function of model
The shift to using vector field has altered the underlying system. These vectors work well for small passages (or chunks). The strategy then is if you have a larger document, you need to break it up into smaller pieces. In addition, these smaller pieces need to be correlated to the primary document and when you are scoring a query against these smaller pieces it becomes difficult to create a score to the query on the ‘document’ and there is an explosion of computing requirements (storage, ram, and compute).
Enter ColBERT: A Hybrid Approach for Effective Retrieval
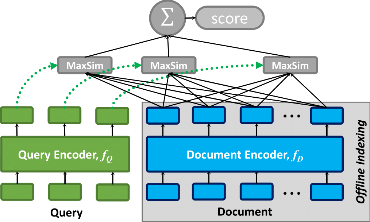
ColPali: Expanding Multimodal Capabilities
The “godfather” of these new approaches is ColBERT (Contextualized Late Interaction over BERT). ColBERT is a model, and an algorithm, that takes an approach of breaking the document apart into smaller pieces and uniquely it also does this to the query. Then as it executes the query it summarizes the smaller pieces via a “MaxSum” function. This MaxSum function is also coined as a ‘late interaction’.
A “late interaction” paradigm, is a fancy way to describe a process where the interaction between a query and document happens after encoding, allowing a process that performs efficiently and accurately matching without the high computational cost of full crossattention during retrieval.
So, instead of encoding an entire document or query into a single vector, ColBERT from a “high level”:
- keeps token-level representations - This means that instead of combining the text (which are made into tokens) into a single vector, it keeps the individual token representations (The words are turned into stand along embeddings/vectors) for each word or subword in both the query and the document
- represents each document and query multiple vectors - one for each token (aka word).
- ColBERT functions as a bi-encoder - This means that ColBERT encodes the query and document independently, creating two sets of embeddings: one for the query and one for the document
- Encodes each part in isolation – Which is essentially how traditional search systems work.
- Scores then via MaxSim (Maximum Similarity) - ColBERT introduced this as lateinteraction technique, where the maximum similarity score between each query token and any document token is computed to capture fine-grained relevance between the query and document.
This approach allows for large document relevancy however this is an algorithm and theory that needs to be implemented in your vector databases. This cannot be done, for example, in Lucene very efficiently although there is a Pull Request in progress to address this.
As ColBERT has emerged to redefine relevancy on large documents, ColPali has emerged as an evolution of this approach but incorporates a vision model to perform the embedding. Where ColBERT focuses on efficient late interaction for text, Colpali uses screenshots to process multimodal data with a similar approach. This approach takes a screenshot of each of the document pages and breaks it down into 1024 “patches” which represent a dissection of 32x32 of the document with an additional 6 text embeddings for text for a total of 1030. Embeddings are created from Gemma 2B which are then transformed into a lower dimension (128) to save storage. The result is a multi-vector vector.
On the query side, like ColBERT, a ranking formula performs a score for each term of the query to each part of the document and then the sum of the scores for the most similar patch for all the terms of the document.
This is a “novel approach” in so far as it does not require you to deconstruct the document during ingestion and can produce highly relevant results-based tables and graphs which have their context lost in OCRing. That said, the model and engine itself are not necessarily scalable and require retrofitting into your vector database / search engine. One of the changes to integrate this is that the index embedding looks like this:

That is 1030 128 dimensions vectors or, 131840 numbers. That is 527,360 bytes or 527k, per page. Vespa’s example handles this but converting the bytes to bits which makes it more like 16k. In addition to the size being challenging the shape and the ability to sum across the segments are challenging to most systems because of how they store the vector or dense_field.
Vespa has created a nice article on how to implement this at scale as has Daniel Van Strien with using QDrant
When Should You Use ColBERT or ColPali?
Something to remember is that there is theory and then there is your use case. If your content passages are long and you are seeing longer form queries, then ColBERT is potentially a solution that will improve your ranking and therefore your relevance. Its ability to understand context and provide semantically relevant results makes it ideal for scenarios where user intent is critical and where keyword-based matching falls short.
For applications involving multimodal data (like images, PDFs, structured product information, and text), Colpali becomes a compelling choice. Its versatility allows it to understand queries involving a mixture of modalities and context, providing a cohesive response that considers the entirety of the data’s context. This makes Colpali especially relevant for use cases involving legal, regulations, financial data or other non-structured use cases.
Conclusion
In conclusion, the development and implementation of these new models and algorithms are a significant advancement in how Vector Search is evolving. These changes are pushing the bounds to what the platforms can support and that needs to be considered when you start your project.
Using these models not only enhances your data processing capabilities but also provides a robust framework for future innovations. By integrating multiple retrieval models, we have created a versatile and scalable solution that meets the diverse needs of our users. As we move forward, continuous improvements and adaptations will ensure that the system remains at the forefront of technological advancements, ultimately driving better decision-making and operational efficiency.
Engage with MC+A Trusted AdvisorTake AI to the Next Level
Launch your technology project with confidence. Our experts allow you to focus on your project’s business value by accelerating the technical implementation with a best practice approach. We provide the expert guidance needed to enhance your users’ search experience, push past technology roadblocks, and leverage the full business potential of search technology.