Streamlining Real-Time Data with Debezium and Elasticsearch
AIeCommerceElasticsearch
May 3, 2022
Engagement Background
In the ultra-competitive vertical of B2C ecommerce search, real-time data processing is a cornerstone technology that ensures the most relevant product information is available for consumption by the search system to provide the best experience to users. Data streaming also provides significant performance improvements for indexing large data sets, as well as improvements on the front end by allowing the most up-to-date data to be incorporated into a custom search ranking algorithm. This includes fields like inventory levels, product location, pricing, and merchant reputation. This provides additional relevancy signals that enable personalization of the search experience. Incorporating this is a custom solution and not out of the box with Elasticsearch.The Engagement
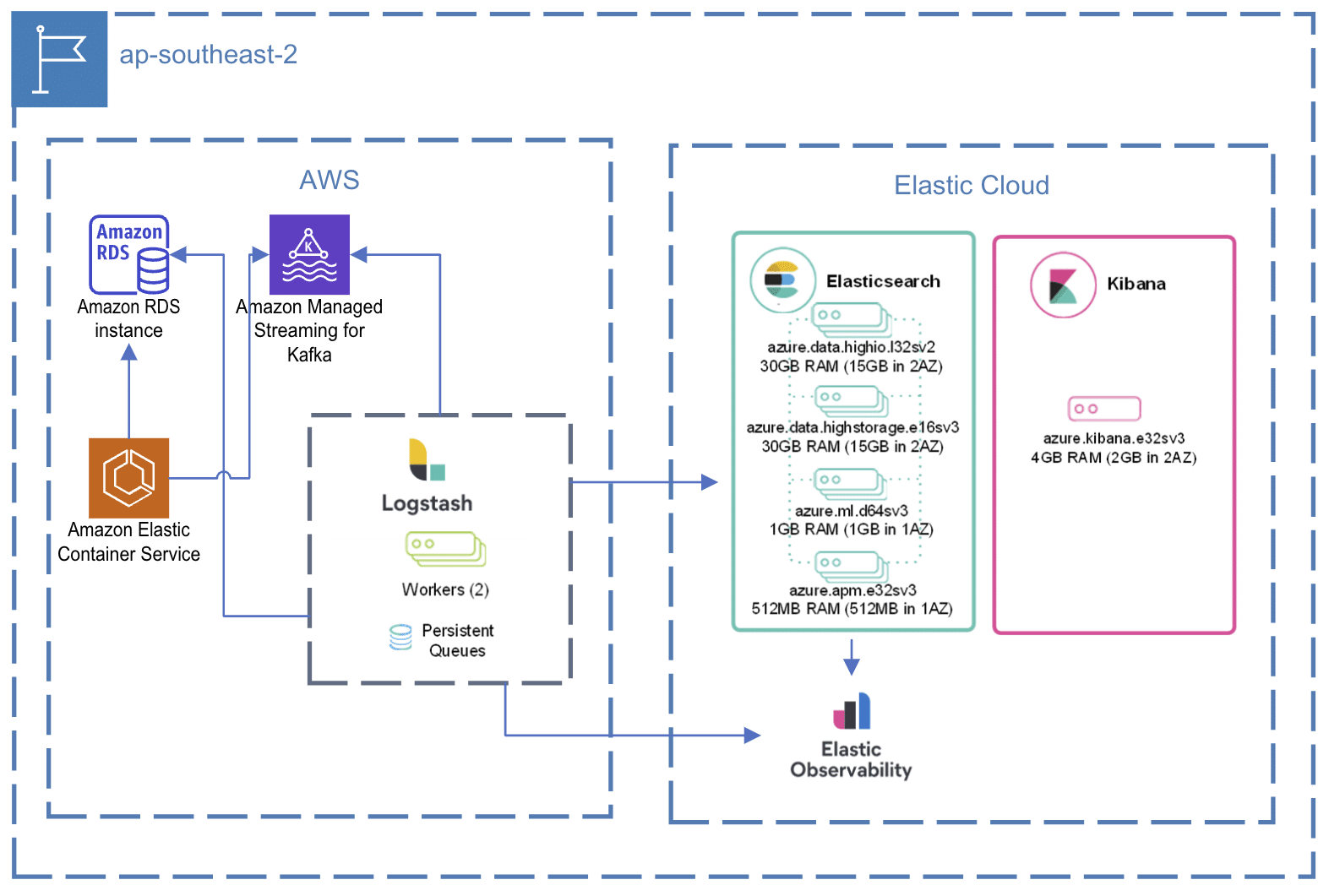
During this project, we identified real-time data processing as a crucial feature to the success of the search implementation. Without a data streaming integration to provide relevance signals, we would have had to fall back on traditional, more static relevance tuning solutions. Relevance tuning is critical to optimizing the user experience of search but can be a time-consuming process when done manually and the legacy tools do not meet consumer expectations. The cycle of reviewing metrics, tuning, adjusting, and testing is resource-intensive and can be a challenge for an organization to maintain. Data streaming allows these constantly updated attributes to be brought into the relevancy formula to promote items that are in stock for example in the result set. This led us to Debezium, an open-source distributed platform for Change Data Capture (CDC), to provide the stream of updates which we transformed into documents that were then indexed with Elasticsearch.The result? We achieved near real-time updates to a search index that contained over 50M in deals and promotions. This removed the need for additional calls for dynamic fields like inventory level and pricing, as well as made updating the search catalog dramatically more efficient, as we only needed to index what had changed. Additionally, this integration allowed for filtering of out-of-stock items, boosting results from favorable merchants based on backend business rules and providing top deals in near real-time with the most accurate price available.The platform that we were integrating with was significant. For this project was designed to handle anywhere from 50 million to 100 million deals. These deals represented product variations of millions of known master products, and with more products came more updates. The system routinely got between 1,000 and 3,000 updates per second. These updates could be new products and updates to the existing products including the price, view count, or something about the merchant. Like many B2C commerce solutions, our implementation featured search-powered navigation because it performs faster and is significantly cheaper than scaling the database with read replicas that could not be cached due to the ever-changing underlying data.An ongoing challenge in the project was the lack of robust or consistent documentation on the Debezium site and because the CDC technology is tied per table, we had to monitor multiple tables and reconstruct the resulting relationship. These are small prices to pay for the performance that was achieved.The Solution
The ultimate solution was one where Debezium fed into Amazon Managed Kafka to be read by a cluster of Logstash nodes. These Logstash nodes contained listeners for the various types of records published. When the documents were processed by Logstash, any missing information could be applied, and the data transformed into more search-friendly values.By deploying Debezium connectors, we created a stream of updates that could be further processed as necessary. These streams were then consumed by a custom-built Logstash pipeline that transformed the data from the Debezium format into a format suitable for Elasticsearch, ensuring that the search indices were always up to date. Additionally, metrics were sent to an Observability cluster to monitor any potential back-ups proactively.