
Comparing Performance of OpenAI GPT-4 and Microsoft Azure GPT-4
Introduction
If you follow online discussions around OpenAI’s API and GPT models, you have undoubtedly come across people discussing the response times / performance of the OpenAI API and that during peak times, performance takes a hit. If you’re building a business that is using any of the OpenAI models, variations in performance and just overall low performance will likely be a concern for you.
OpenAI and Microsoft both provide API services to utilize OpenAI’s GPT models. There are variations in their terms of services, and for most businesses, utilizing GPT via Microsoft Azure provides additional privacy controls that aren’t available when utilizing OpenAI’s API. Beyond that, the models are meant to behave the same way (assuming you’re using the same version of the model on both platforms). Though the biggest question in my mind, and one that I've seen anecdotal evidence for, is, do they provide the same performance.
Within this article (short as it is), we will be evaluating the performance of OpenAI's vs Microsoft's API when utilizing GPT-4.
Testing Methodology
We will be following the below conditions for testing;
- We will use OpenAI’s Python SDK. Specifically, version 0.27.8
- All tests will be run from the same machine, WSL2 via Windows 11
- We will measure and account for latency to each endpoint and remove this as a factor in the results
- For Azure, we will be using the Australia region
- For OpenAI, we cannot elect a region and will be using their standard endpoint
- We will execute each test 10 times against each providers API
- We will record the individual results of each test run and aggregate the results for measurement
- The model temperature will be set to 0.0 for both services
NOTE: This is not a scientific approach to testing. It may not account for all variations between the services and as such, this should be used as a guide only. Your experiences may differ.
We will complete a number of tests against each service to measure performance of different types of prompts and message chains:
| Test Name | Description |
|---|---|
| No system prompt, single message | No custom system prompt will be sent, just a single basic message payload |
| No system prompt, 10 message thread | No custom system prompt will be sent, a thread of 9 messages will be sent |
| Custom system prompt, single message, technical question | Customised system prompt for a technical role and a single message thread |
| Custom system prompt, 10 message thread, technical question | Customized system prompt for a technical role and a thread of 9 messages |
| Data Extraction and JSON Generation | No system prompt, a single message asking GPT-4 to extract items from the text and return a JSON list |
The Results
Pictures are worth a thousand words.
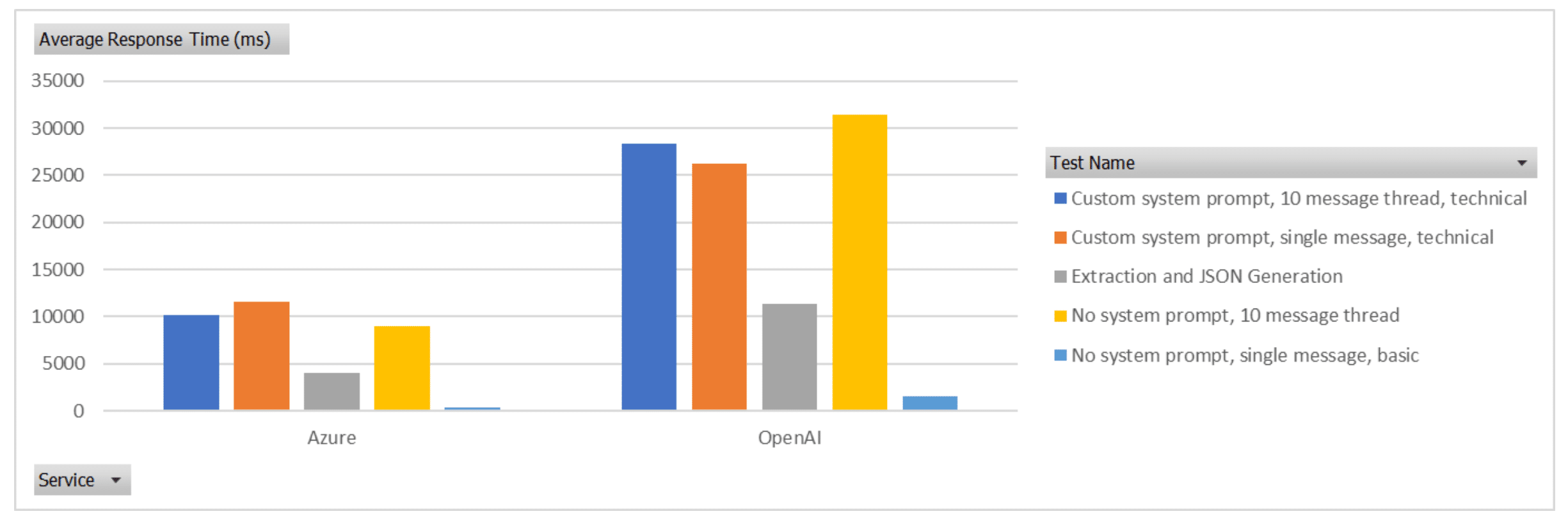
As is clearly shown in the image above (and further highlighted in the below), the performance difference is quite extreme between Azure and OpenAI. On average, GPT-4 via OpenAI API was 2.8 times slower than Microsoft Azure.
The amount of tokens that needed to be generated in the response can impact the time to respond, if one service was providing significantly longer responses, that will result in a longer completion time. The below image displays the average tokens generated per second for each service. Again, Azure significantly outperforms OpenAI by a factor of 2.77 times.
One item of note here was, even with temperature of 0 on both services, OpenAI returned variations in the response and number of tokens generated. Azure was far more consistent in its response being the same each time (this in itself is worthy of note).
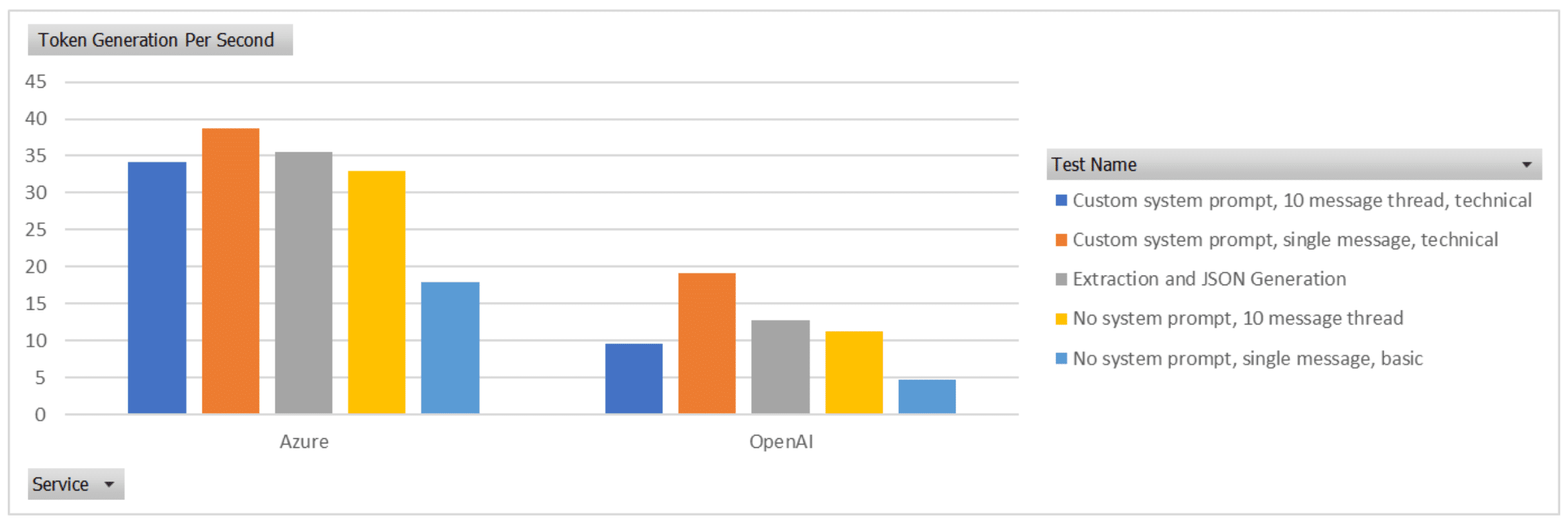
So, we’ve looked at the aggregate of all results and compared, what about the specific tests, what impact do the variances in the messages sent, instructions, response format and length have?
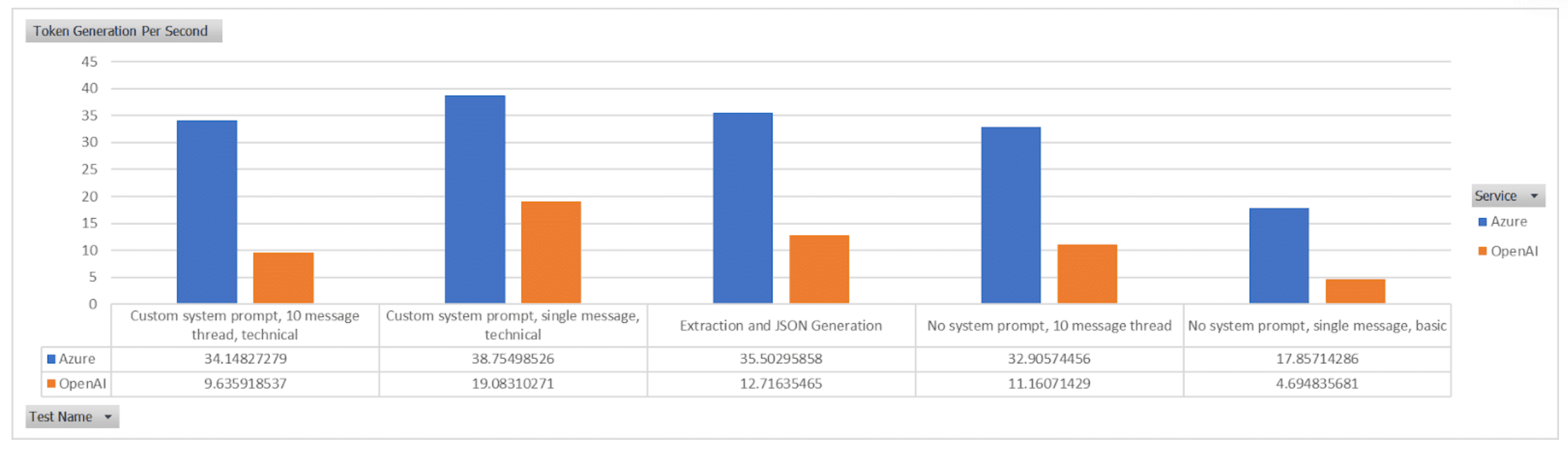
The variance in tokens generated per second is most pronounced in the test “Custom system prompt, 10 message thread, technical” with Azure generating tokens per second at a rate of 3.54 times more than that of OpenAI.
The smallest variance was in the “Custom system prompt, single message, technical” test, with Azure generating tokens at a rate of 2.03 times faster than that of OpenAI.
This article isn’t intended to go into why this variation may exist and why we see different variations in different tests, and honestly, it’s probably beyond the capability of us to be able to decipher the reasoning. The end result is, there are variations in completion times for each service, which differ depending on the length, content, response request etc.
The aggregate results of each test are below if you’re interested in the details.
| Test Name | Service | Test Count | Average Response Time (ms) | Average Response Time Accounting for Latency (ms) | prompt tokens | completion tokens | Total Tokens (Per Test) | Token Generation Per Second |
|---|---|---|---|---|---|---|---|---|
| No system prompt, single message, basic | Azure | 10 | 392.05 | 368.05 | 14 | 7 | 21 | 17.85714286 |
| No system prompt, single message, basic | OpenAI | 10 | 1491.17 | 1478.17 | 14 | 7 | 21 | 4.694835681 |
| No system prompt, 10 message thread | Azure | 10 | 8989.99 | 8965.99 | 1930 | 295 | 2225 | 32.90574456 |
| No system prompt, 10 message thread | OpenAI | 10 | 31360.18 | 31347.18 | 1930 | 338-360 | 2268 - 2290 | 11.16071429 |
| Custom system prompt, single message, technical | Azure | 10 | 11558.03 | 11534.03 | 91 | 447 | 538 | 38.75498526 |
| Custom system prompt, single message, technical | OpenAI | 10 | 26201.19 | 26188.19 | 91 | 363-428 | 454-519 | 19.08310271 |
| Custom system prompt, 10 message thread, technical | Azure | 10 | 10103.63 | 10079.63 | 1802 | 345 | 2147 | 34.14827279 |
| Custom system prompt, 10 message thread, technical | OpenAI | 10 | 28398.97 | 28385.97 | 1802 | 345-391 | 2147-2193 | 9.635918537 |
| Extraction and JSON Generation | Azure | 10 | 4056.21 | 4032.21 | 74 | 144 | 218 | 35.50295858 |
| Extraction and JSON Generation | OpenAI | 10 | 11324.54 | 11311.54 | 74 | 144 | 218 | 12.71635465 |
Conclusion
We were taken back by the performance difference between OpenAI and Azure. I suspected from our experience that there were variations, but not to the level that we have seen here. For any business that is looking to use GPT-4 or other OpenAI models internally or as part of a product, it is clear that if performance is a consideration, then Azure is the better service to use.The Details
All test prompts and results can be found on GitHub.
About the Author
Russell Proud is the co-founder of Decided.ai, an Conversational Search and Discovery platform for eCommerce retailers. Russell has spent the last 20 years building technology and services and provides consulting services for companies in AI, Search, Discovery, LLMs and other technical areas.
Recent Insights
Engage with MC+A Trusted AdvisorGo Further with Expert Consulting
Launch your technology project with confidence. Our experts allow you to focus on your project’s business value by accelerating the technical implementation with a best practice approach. We provide the expert guidance needed to enhance your users’ search experience, push past technology roadblocks, and leverage the full business potential of search technology.